Measuring developer productivity via humans
Qualitative metrics provide a critical understanding of developer productivity that cannot be obtained from system data alone.

Somewhere right now, a technology executive tells their directors, “We need a way to measure the productivity of our engineering teams.” A working group assembles to explore potential solutions, and weeks later, it proposes implementing the metrics: lead time, deployment frequency, and number of pull requests created per engineer.
Soon after, senior engineering leaders meet to review their newly created dashboards. Immediately, questions and doubts are raised. One leader says: “Our lead time is two days, which is ‘low performing’ according to those benchmarks – but is there a problem?”. Another leader says: “It’s unsurprising to see that some of our teams are deploying less often than others. But I’m not sure why or what to do.”
If this story arc is familiar to you, don’t worry – it’s familiar to most, including some of the biggest tech companies in the world. It is not uncommon for measurement programs to fall short when metrics like DORA fail to provide the depth for insights leaders need.
The solution relies on capturing insights from developers themselves rather than solely relying on basic measures of speed and output. What we are referring to here is qualitative measurement. We’ve helped many organizations adopt this approach and have seen firsthand the dramatically improved understanding of developer productivity it provides.
In this article, we provide a primer on this approach derived from our experience helping many organizations on this journey. We begin by defining qualitative metrics and how to advocate for them. We follow with practical guidance on how to capture, track, and utilize this data.
Today, developer productivity is a critical concern for businesses amid fiscal tightening and transformational technologies such as AI. In addition, developer experience and platform engineering garner increased attention as enterprises look beyond Agile and DevOps transformation. All these concerns share a reliance on measurement to help guide decisions and track progress. And for this, qualitative measurement is key.
What is a qualitative metric?
We define a qualitative metric as a measurement derived from self-reported data. This is a practical definition – we haven’t found a singular definition within the social sciences, and the alternative definitions we’ve seen have flaws that we discuss later in this section.
The definition of the word “metric” is unambiguous. The term “qualitative,” however, has no authoritative definition, as noted in the 2019 journal paper What is Qualitative in Qualitative Research: “There are many definitions of qualitative research, but if we look for a definition that addresses its distinctive feature of being ‘“qualitative,’” the literature across the broad field of social science is meager. The main reason behind this article lies in the paradox, which, to put it bluntly, researchers act as if they know what it is but cannot formulate a coherent definition.”
An alternate definition we’ve heard is that qualitative metrics measure quality while quantitative metrics measure quantity. We’ve found this definition problematic for two reasons: first, the term “qualitative metric” includes the term metric, which implies that the output is a quantity (i.e., a measurement). Second, quality is typically measured through ordinal scales that are translated into numerical values and scores, which, again, contradicts the definition.

Another argument we have heard is that the output of sentiment analysis is quantitative because the analysis results in numbers. While we agree that the data resulting from sentiment analysis is quantitative, based on our original definition this is still a qualitative metric (i.e., a quantity produced qualitatively) unless one were to take the position that “qualitative metric” is altogether an oxymoron.
Aside from the problem of defining what a qualitative metric is, we’ve also encountered problematic colloquialisms. One example is the term “soft metric.”. We caution against this phrase because it harmfully and incorrectly implies that data collected from humans is weaker than “hard metrics” collected from systems. We also discourage the term “subjective metrics” because it misconstrues that data collected from humans can be either objective or subjective—as discussed in the next section.
Advocating for qualitative metrics
Executives are often skeptical about the reliability and usefulness of qualitative metrics. Even highly scientific organizations like Google have had to overcome these biases. Engineering leaders are inclined toward system metrics since they are accustomed to working with telemetry data to inspect systems. However, we cannot rely solely on system data to measure people.
We’ve seen some organizations get into an internal “battle of the metrics,” which is not a good use of time or energy. Our advice for champions is to avoid pitting qualitative and quantitative metrics against each other as an either/or. It’s better to make the argument that they are complementary tools – as we cover at the end of this article.
We’ve found that the underlying cause of opposition to qualitative data is misconceptions, which we address below. Later in this article, we outline the distinct benefits of self-reported data, such as its ability to measure intangibles and surface critical context.
Misconception: Qualitative data is only subjective
Traditional workplace surveys typically focus on their employees’ subjective opinions and feelings. Thus, many engineering leaders intuitively believe that surveys can only collect subjective data from developers.
As described in the following section, surveys can also capture objective information about facts or events. Google’s DevOps Research and Assessment (DORA) program is an excellent concrete example.
Some examples of objective survey questions:
- How long does it take to go from code committed to code successfully running in production?
- How often does your organization deploy code to production or release it to end users?
Misconception: Qualitative data is unreliable
One challenge of surveys is that people with all manner of backgrounds write survey questions without special training. As a result, many workplace surveys do not meet the minimum standards needed to produce reliable or valid measures. Well-designed surveys, however, produce accurate and reliable data (we provide guidance on how to do this later in the article).
Some organizations have concerns that people may lie in surveys, which can happen in situations where there is fear around how the data will be used. In our experience, when surveys are deployed to help understand and improve bottlenecks affecting developers, respondents are not incentivized to lie or game the system.
While it’s true that survey data isn’t always 100% accurate, we often remind leaders that system metrics are often imperfect, too. For example, many organizations attempt to measure CI build times using data aggregated from their pipelines, only to find that it requires significant effort to clean the data to produce an accurate result.
The two types of qualitative metrics
There are two key types of qualitative metrics:
- Attitudinal metrics capture subjective feelings, opinions, or attitudes toward a specific subject. An example of an attitudinal measure would be the numeric value captured in response to the question: “How satisfied are you with your IDE, on a scale of 1-10?”.
- Behavioral metrics capture objective facts or events pertaining to an individual’s work experiences. An example of a behavioral measure would be the quantity captured in response to the question: “How long does it take for you to deploy a change to production?”
We’ve found that most tech practitioners overlook behavioral measures when thinking about qualitative metrics. This occurs despite the prevalence of qualitative behavioral measures in software research, such as Google’s DORA program mentioned earlier.
DORA publishes annual benchmarks for metrics such as lead time for changes, deployment frequency, and change failure rate. Unbeknownst to many, DORA’s benchmarks are captured using qualitative methods with the survey items below.

We’ve found that the ability to collect attitudinal and behavioral data at the same time is a powerful benefit of qualitative measurement.
For example, behavioral data might show you that your release process is fast and efficient. However, only attitudinal data can tell whether it is smooth and painless, which has important implications for developer burnout and retention.
To use a non-tech analogy, imagine you’re feeling sick and visit a doctor. The doctor checks your blood pressure, temperature, and heart rate, then says, “Well, it looks like you’re all good. There’s nothing wrong with you.” You would be taken aback and say, “Wait, I’m telling you that something feels wrong!”
The benefits of qualitative metrics
One argument for qualitative metrics is that they avoid subjecting developers to the feeling of “being measured” by management. While we’ve found this true—especially when compared to metrics derived from developers’ Git or Jira data—it doesn’t address the main objective benefits that qualitative approaches can provide.
There are three main benefits of qualitative metrics when it comes to measuring developer productivity:
Qualitative metrics allow you to measure things that are otherwise unmeasurable
System metrics like lead time and deployment volume capture what’s happening in our pipelines or ticketing systems. But many more aspects of developers’ work need to be understood in order to improve productivity: for example, whether developers are able to stay in the flow of work or easily navigate their codebases. Qualitative metrics let you measure these intangibles that are otherwise difficult or impossible to measure.
An interesting example of this is technical debt. At Google, a study to identify metrics for technical debt included an analysis of 117 metrics that were proposed as potential indicators. To the disappointment of Google researchers, no single metric or combination of metrics was found to be valid indicators.
While an undiscovered objective metric for technical debt may exist, this may be impossible because technical debt assessment relies on comparing the current state of a system or codebase with its imagined ideal state. In other words, human judgment is essential.
Qualitative metrics provide missing visibility across teams and systems
Metrics from ticketing systems and pipelines give us visibility into some of the developers’ work. However, this data alone cannot give us the full story. Developers do a lot of work that’s not captured in tickets or builds: for example, designing key features, shaping the direction of a project, or helping a teammate get onboarded.
It’s impossible to gain visibility into all these activities through data from our systems alone. And even if we could theoretically collect all the data through systems, there are additional challenges to capturing metrics through instrumentation.
One example is the difficulty of normalizing metrics across different team workflows. For example, if you’re trying to measure how long tasks take from start to completion, you might try to get this data from your ticketing tool. However, individual teams often have different workflows that make it difficult to produce an accurate metric. In contrast, simply asking developers how long tasks typically take can be much simpler.
Another common challenge is cross-system visibility. For example, a small startup can measure TTR (time to restore) using an issue tracker such as Jira. However, A large organization will likely need to consolidate and cross-attribute data across planning systems and deployment pipelines to gain end-to-end system visibility. This can be a yearlong effort, whereas capturing this data from developers can provide a baseline quickly.
Qualitative metrics provide context for quantitative data
As technologists, it is easy to focus heavily on quantitative measures. They seem clean and clear, after all. There is a risk, however, that the full story isn’t being told without richer data and may lead us to focus on the wrong thing.
One example of this is code review: a typical optimization is to try to speed up the code review. This seems logical, as waiting for a code review can cause wasted time or unwanted context switching. We could measure the time it takes to complete reviews and incentivize teams to improve it. However, this approach may encourage negative behavior: reviewers may rush through reviews, or developers may not find the right experts to perform reviews.
Code reviews exist for an important purpose: to ensure high-quality software is delivered. If we do a more holistic analysis—focusing on the outcomes of the process rather than just speed—we find that optimizing code review must ensure good code quality, mitigation of security risks, building shared knowledge across team members, and ensuring that our coworkers aren’t stuck waiting. Qualitative measures can help us assess whether these outcomes are being met.
Another example is the developer onboarding process. Software development is a team activity, so if we only measure individual output metrics—such as the rate at which new developers are making commits or the time to first commit—we miss important outcomes. For instance, we may overlook whether we are fully utilizing the ideas that developers contribute, whether they feel safe asking questions, and whether they are collaborating with cross-functional peers.
How to capture qualitative metrics
Many tech practitioners don’t realize how difficult it is to write good survey questions and design good survey instruments. In fact, whole fields of study related to this exist, such as psychometrics and industrial psychology. It is important to bring or build expertise here when possible.
Below are a few good rules for writing surveys to avoid the most common mistakes we see organizations make:
- Survey items must be carefully worded, and every question should only ask one thing.
- If you want to compare results between surveys, be careful about changing the wording of questions such that you’re measuring something different.
- If you change any wording, you must do rigorous statistical tests.
In survey parlance, ”good surveys” means “valid and reliable” or “demonstrating good psychometric properties.” Validity is the degree to which a survey item measures the construct you desire to measure. Reliability is the degree to which a survey item produces consistent results from your population over time.
One way of thinking about survey design that we’ve found helpful to tech practitioners is to think of the survey response process as an algorithm in the human mind.
When an individual is presented with a survey question, a series of mental steps take place to arrive at a response. The model below is from the seminal 2012 book The Psychology of Survey Response:
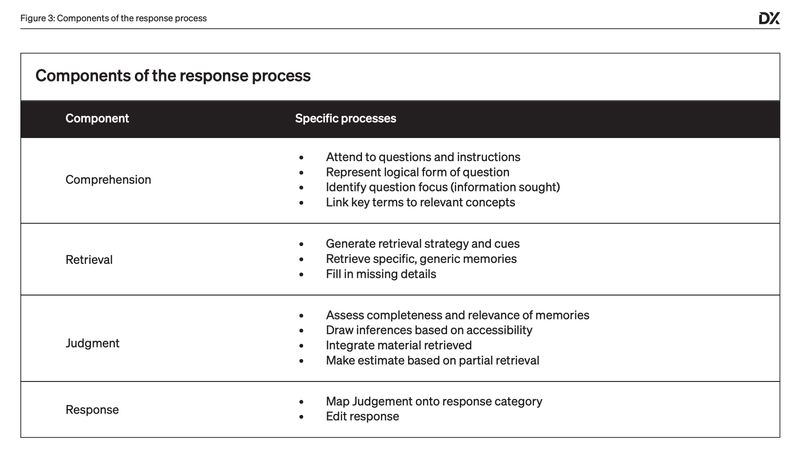
Decomposing the survey response process and inspecting each step can help us refine our inputs to produce more accurate survey results. Developing good survey items requires rigorous design, testing, and analysis—just like designing software!
However, good survey design is just one aspect of running successful surveys. Additional challenges include participation rates, data analysis, and knowing how to act on data. Below are some of the best practices we’ve learned.
Segment results by team and persona
A common mistake organizational leaders make is focusing on companywide results instead of data broken down by team and persona (e.g., role, tenure, seniority). As previously described, developer experience is highly contextual and can differ radically across teams or roles. Focusing only on aggregate results can lead to overlooking problems affecting small but important company populations, such as mobile developers.
Free text comments are often the most valuable
We’ve been discussing qualitative metrics, but free-text comments are an extremely valuable form of qualitative data. In addition to describing friction or workflow, developers often share great ideas to improve their experience. Free-text responses allow us to capture these insights and identify individuals to follow up with. They can also highlight areas your survey did not address, which could be included in future surveys.
Compare results against benchmarks
Comparative analysis can help contextualize data and help drive action. For example, developer sentiment toward code quality commonly skews negative, making it difficult to identify true problems or gauge their magnitude. The more actionable data point is: “Are our developers more frustrated about code quality than other teams or organizations?” Teams with lower sentiment scores than their peers and organizations with lower scores than their industry peers can surface notable opportunities for improvement.
Use transactional surveys where appropriate
Transactional surveys capture feedback during specific touchpoints or interactions in the developer workflow. For example, platform teams can use transactional surveys to prompt developers for feedback while creating a new service in an internal developer portal. Transactional surveys can also augment data from periodic surveys by producing higher-frequency feedback and more granular insights.
Avoid survey fatigue
Many organizations struggle to sustain high participation rates in surveys over time. Lack of follow-up can cause developers to feel that repeatedly responding to surveys is not worthwhile. Therefore, it is critical that leaders and teams follow up and take meaningful action after surveys. While a quarterly or semi-annual survey cadence is optimal for most organizations, we’ve seen some organizations succeed with more frequent surveys integrated into regular team rituals such as retrospectives.
Using qualitative and quantitative metrics together
Qualitative metrics and quantitative metrics are complementary approaches to measuring developer productivity. Qualitative survey metrics provide a holistic view of productivity, including subjective and objective measurements. Quantitative metrics, on the other hand, provide distinct advantages as well:
- Precision. Humans can tell you whether their CI/CD builds are generally fast or slow (i.e., whether durations are closer to a minute or an hour), but they cannot report on build times down to millisecond precision. Quantitative metrics are needed when a high degree of precision is needed in our measurements.
- Continuity. Typically, an organization can survey its developers only once or twice per quarter. To collect more frequent or continuous metrics, organizations must gather data systematically.
Ultimately, organizations can gain maximum visibility into developers’ productivity and experience by combining qualitative and quantitative metrics—a mixed-methods approach. So, how do you use qualitative and quantitative metrics together?
We’ve seen organizations find success when they start with qualitative metrics to establish baselines and determine where to focus. Then, follow with quantitative metrics to help drill deeper into specific areas.
Engineering leaders find this approach effective because qualitative metrics provide a holistic view and context, allowing for a wide understanding of potential opportunities. Quantitative metrics, on the other hand, are typically only available for a narrower set of the software delivery process.
Google advises its engineering leaders to consult survey data before examining log data. Google engineering researcher Ciera Jaspan explains, “We encourage leaders to look at the survey data first because relying solely on log data doesn’t reveal whether something is good or bad. For instance, we have a metric that tracks the time taken to implement a change, but that number is meaningless. You can’t determine if it’s a good thing or a bad thing or if there’s a problem.”
A mixed-methods approach allows us to take advantage of the benefits of both qualitative and quantitative metrics while getting a full understanding of developer productivity:
- Start with qualitative data to identify your top opportunities
- Once you know what you want to improve, use quantitative metrics to drill in further
- Track your progress using both qualitative and quantitative metrics
It is only by combining as much data as possible—both qualitative and quantitative—that organizations can begin to build a full understanding of developer productivity.
In the end, however, it’s important to remember that organizations spend a lot on highly qualified humans who can observe and detect problems that log-based metrics can’t. By tapping into the minds and voices of developers, organizations can unlock insights previously seen as impossible.
About the authors
Abi Noda is DX’s co-founder and CEO, leading the company’s strategic direction and R&D efforts. Tim Cochran is a Principal in Amazon’s Software Builder Experience (ASBX) group.
The authors wish to thank Martin Fowler, Laura Tacho, Max Kanat-Alexander, Laurent Ploix, Bethany Otto, Andrew Cornwall, Carol Costello, and Vanessa Towers for their feedback on this article.
This article was originally published on martinfowler.com.