AI summarization in DX

Tyler Wray
Product lead
DX customers utilize survey comments to set goals for upcoming improvements. But reading and analyzing comments can be a daunting task. Many DX customers capture thousands or even tens of thousands of thoughtful comments in their surveys… These comments contain crucial insights for leaders, but manually reading, understanding, and collating all those responses can take a very long time. Our solution? AI summarization.
When our team began exploring how to build AI summarization into our product, we assumed it would be simple. “How hard can this be?”, we thought. “This is just a ChatGPT API call, right?”, “I’ll have this done in a day”. This turned out to be naive thinking, as there were numerous considerations and intricacies that we eventually had to solve for.
In this article, I’ll cover the journey we went through in building our AI summarization feature and what we learned along the way, including:
- GPT models - rate limiting, temperature, hallucination
- Context tokens
- OpenAI’s different APIs
- Recursive summarization
- Chain of density
- Cost modeling
- Data privacy
Our initial attempt
To get started, we grabbed some OpenAI credentials and wrote a quick background job using the OpenAI API to generate a summary of all user comments in a survey. The API received a prompt and returned a ChatGPT response. We were elated to have a prototype up and running quickly! Then we started feeding it a larger number of comments and realized things wouldn’t be as easy as we’d hoped.
Two problems reared their heads immediately.
First, we discovered that there was a difference between the completions API and the chat-completions API . Chat-completions is the newer API. Whoops! AI industry knowledge is shifting so quickly that learning material only 6 months old was already “legacy”! We didn’t realize we used a legacy API until we saw the deprecation in the OpenAI docs.
Second, we had too many comments! They didn’t all fit inside the context token limit of the basic model we were using at the time, `gpt-3.5-turbo`. This resulted in an error from the API, and was ultimately the most difficult problem we would encounter in this project.
Learning key concepts
After this experience, our heads were filled with questions and so we spent time learning as a team about core AI concepts. What is a model? What are context tokens? What is a GPT? What is a prompt, and what is prompt-engineering? Below, we summarize these concepts and some of the resources that we found helpful:
- GPT - Stands for “Generative Pre-trained Transformers”. This is a type of AI text generation model. GPT is the architecture type of AI models of which a neural network is trained to take text commands and generate text responses. Originally GPT’s were only designed to work with text, but the latest models can also work with images.
- OpenAI model - OpenAI’s implementation of a GPT (docs). This is `gpt-4`, `gpt-3.5-turbo`, etc. Choosing a model can be tricky and requires a tradeoff between cost, quality, context token requirements, and your specific AI use-case.
- Context Tokens - A token is a chunk of text broken up by the model to process text. A context token limit is the maximum amount of context a model can process. OpenAI recently updated its token limits for its latest GPT models, so running into context token limits is less of a concern. However if you’re dealing with large amounts of text you’ll need to be aware of the context limits and make that tradeoff when choosing a model.
- Prompt - The instructions given to a model specifying how to generate text. A prompt is any instruction you give to a GPT model. Some examples may be “Write a 2 minute kids bedtime story featuring a main character named Lyla” or “Write a javascript function to sort an array of objects with a date field called ‘timestamp’”. Prompts are not exclusive to ChatGPT, all GPT’s require a prompt to generate text.
- Prompt Engineering - Implementing strategies to craft better prompts to elicit higher-quality responses from a model. Good prompt engineering requires understanding how models process prompts and generate text.
Understanding these core concepts was key to unblocking ourselves and moving forward. Each layer of knowledge gained unlocked more questions and directed our research in the right direction. In the next sections of this article, I’ll cover how we applied these concepts in our own feature implementation.
Cost modeling
Determining how much your AI features will cost is an important consideration. With OpenAI, cost is based on the GPT model you choose, how many tokens are in the prompt, and how many tokens are in the generated text. OpenAI offers a library called tiktoken which lets you quickly determine the token size of a prompt. We wrote a quick script using tiktoken in Ruby to estimate our costs for customers so we weren’t surprised by our OpenAI bill after deploying our AI summarization feature.
Data privacy
We had some early beta customers rightfully cautious about data-privacy and ChatGPT. After clarifying that OpenAI API’s don’t use context data to train their models, customers were happy to use the feature. An important distinction here is between ChatGPT the product (chat.openai.com) and the OpenAI GPT platform. ChatGPT is the full-service product provided by OpenAI. OpenAI uses all ChatGPT prompts and responses to further train its own models. The GPT platform provided by OpenAI is exposed via their API. The most important distinction for privacy is that GPT platform usage via the API is not used by OpenAI to further train their model’s.
Recursive summarization
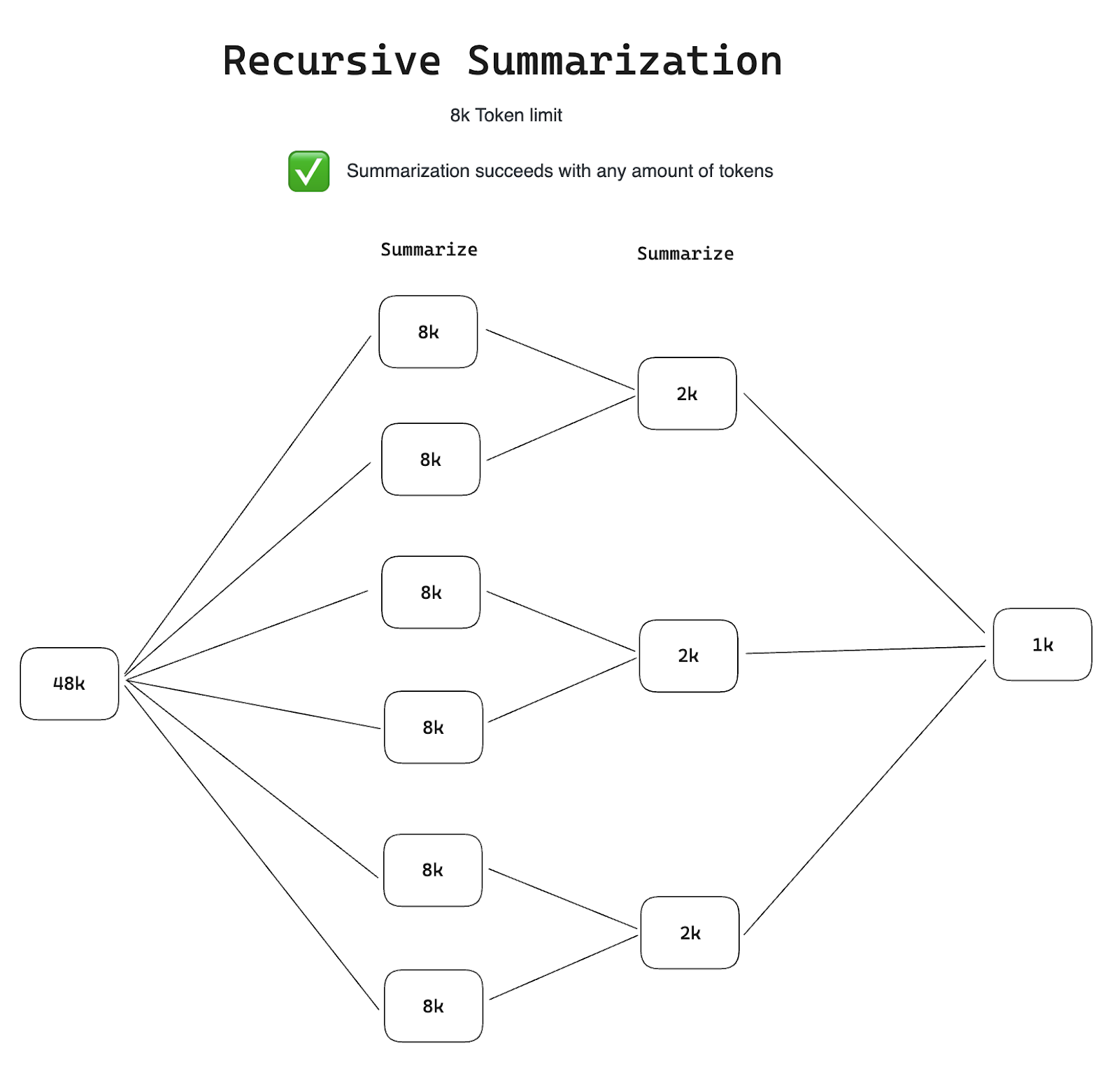
One of the later challenges we faced was exceeding context token limits (i.e., feeding OpenAI too much text at once). Our larger customers have tens of thousands of comments translating to roughly 150,000 tokens, greatly exceeding the 8,000 (at the time) token limit of gpt-4.
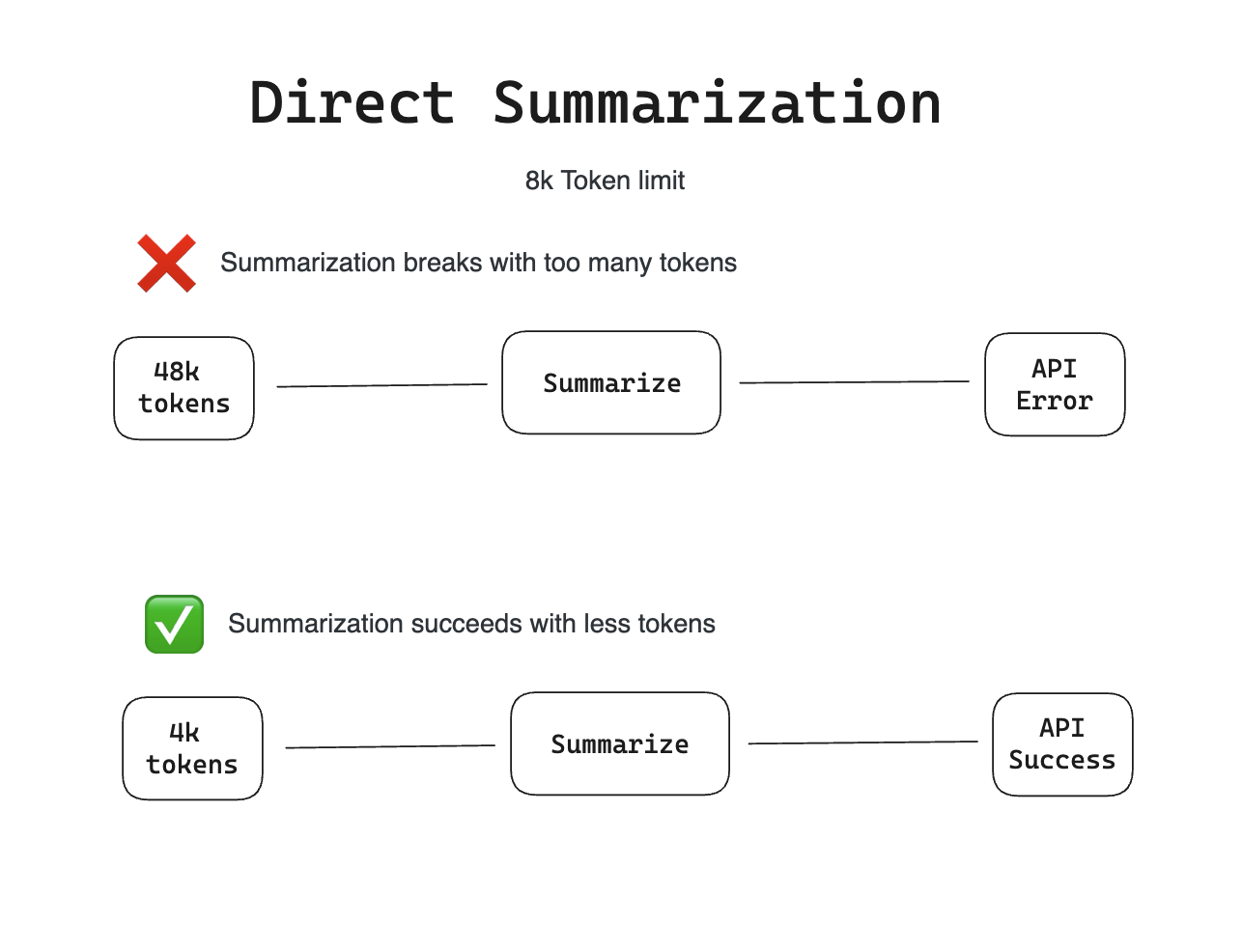
Direct summarization would succeed for smaller DX customers where we did not exceed OpenAI’s context token limit. But this process of direct summarization would fail for larger customers.
To solve this, we used a technique called recursive summarization. With recursive summarization we evaluate the total token size up front and break up the comments into smaller pieces that can be individually summarized. Then after summarizing those chunks; we summarize the summaries until we are left with a single, final, summary!
Chain of Density
One of the challenges of recursive summarization is that details are lost in each round of summarization. In effect, there is a GPT telephone game that plays out, where details found in the original raw content are diluted in each step.
To solve this, we used the Chain of Density Technique. Chain of Density involves asking a GPT to summarize a body of text and continually revise that summary a certain number of times, using more impactful words each time to produce a more concise and rich summary than before.
Here’s an example of the types of iterative prompts we use:
Prompt 1:
| Summarize these comments |
Prompt 2:
| You are a friendly AI who specializes in summarizing bodies of text into a simple, easy to read, concise summary. The summary should be no more than 40 words in length. |
Prompt 3 (Chain of Density):
| You will generate increasingly concise, entity-dense summaries of the Comments. Repeat the following 2 steps 5 times. Step 1. Identify 1-3 informative entities from the comment which are missing from the previously generated summary. Step 2. Write a new, denser summary of identical length which covers every entity and detail from the previous summary plus the Missing Entities. A Missing Entity is: - Relevant: related to developer experience. - Specific: descriptive yet concise (5 words or fewer). - Novel: not in the previous summary. - Faithful: present in the Comments. - Anywhere: located anywhere in the Comment. Guidelines: - The first summary should be long (4-5 sentences, ~80 words) yet highly non-specific, containing little information beyond the entities marked as missing. Use overly verbose language and fillers (e.g., "these comments discuss") to reach ~80 words. - Make every word count: rewrite the previous summary to improve flow and make space for additional entities. - Make space with fusion, compression, and removal of uninformative phrases like "the comment mentions". - The summaries should become highly dense and concise yet self-contained, e.g., easily understood without reading the Comments. - Missing entities can appear anywhere in the new summary. - Never drop entities from the previous summary. If space cannot be made, add fewer new entities. Remember, use the exact same number of words for each summary. |
Chain of Density techniques enabled us to transform our summaries from basic vocabulary and sentence structures like this:
> The Developers are often frustrated with many slow builds in the environment which they code.
To richer summaries like this:
> Building in the new Athena environment is complex and confusing. Increased Deployment steps lead to engineers feeling like a burden to their team.
The second summary has domain-specific keywords and more sophisticated wording in a way that produces richer and more useful content, thanks to the Chain of Density technique.
Wrapping up
Building our AI summarization feature opened our eyes to the full powers and complexities of LLM tools. Since the initial release of this feature last October, we’ve been happy to see it well-received by customers and help them gain more useful insights from their data.
Our team is continuing to explore impactful use cases for AI within the DX suite of products. Conversational interfaces, AI-powered SQL authoring, and AI-generated action item recommendations are just some of the opportunities we are investigating.
We hope that this article gives you useful insight into how DX incorporates AI, and techniques for better leveraging LLMs within your own products and tools.