As AI becomes deeply ingrained in the way organizations deliver software, a new challenge is emerging: understanding why agents succeed or fail. Not whether they’re being used—but whether they’re being set up to be effective.
Over the past decade, the industry has learned that developer effectiveness is not primarily about the individual. It’s about the environment. Developers are most effective when they have short feedback loops, clear context, well-structured systems, and minimal friction. Organizations that invest in understanding and improving these conditions consistently outperform those that don’t.
Agents are no different. An agent’s effectiveness is shaped by the same forces—context, environment, and structure. An agent working against a well-documented, modular codebase with clear instructions will dramatically outperform the same agent working against a monolith with sparse documentation and ambiguous prompts. The difference isn’t the model. It’s the conditions the model is operating in.
To improve agent effectiveness, we need data—the same way we need data about human developer experience to improve developer effectiveness. At DX, we’ve been researching how to unlock this new frontier of intelligence for engineering leaders and development teams. Today, we’re introducing Agent Experience.
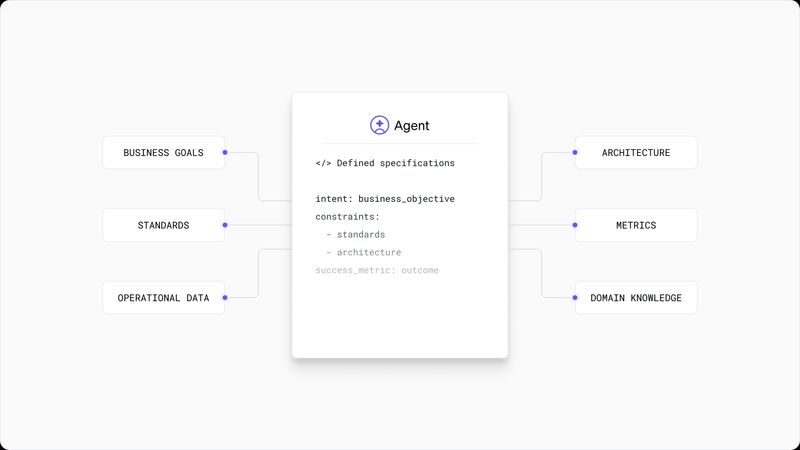
If DX Snapshots are how organizations understand developer experience, Agent Experience is how they understand the experience of their agents. It’s a snapshot for agents—capturing what agents encounter during their work so that organizations can systematically improve the conditions that determine whether agents succeed or fail.
The core insight is simple: you can ask the agent directly. Unlike human developers, who require surveys and sampling to surface friction, agents have full visibility into their own context. They know when documentation is missing, when instructions are ambiguous, when a codebase is difficult to navigate. And because everything is already in context, the agent can use its own reasoning to evaluate its experience in real time.
Agent Experience captures this signal across four components, assessed per session—each scored and accompanied by a qualitative comment from the agent itself explaining what it encountered:
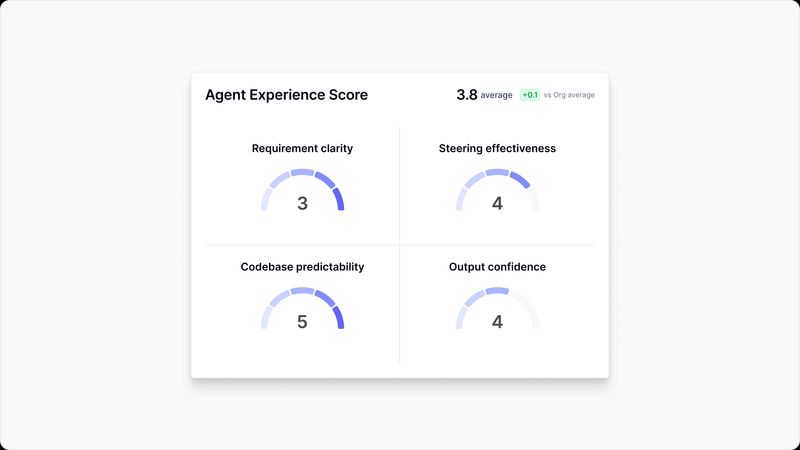
Requirement clarity. Were the task requirements clear and complete? Could the agent determine what was expected without making assumptions or guessing at intent?
Steering effectiveness. Was the agent guided well throughout the session? Did it receive useful course corrections, or did it drift without feedback?
Codebase predictability. Was the codebase structured in a way the agent could reliably navigate? Were conventions consistent, dependencies clear, and patterns predictable enough for the agent to work confidently?
Output confidence. How confident was the agent in the quality and correctness of what it produced? Did it have sufficient signals to validate its own work?
Every session produces an overall score plus these four component scores, each with the agent’s own commentary. This means you’re not just seeing a number—you’re hearing the agent explain why it scored a session the way it did.
Agent Experience data is actionable at every level of the organization.
For platform and enablement teams, it provides a clear map of where to invest in AI readiness. If agents are consistently reporting low codebase predictability in a particular area, that’s a signal to improve documentation, add context files, or restructure how code is organized. If requirement clarity scores are low, it may point to a need for better prompting practices or standardized task templates across teams.
For engineering leaders, it provides a new lens on organizational readiness for agentic software delivery. Rather than measuring agent capability in the abstract, Agent Experience measures whether your organization is creating the conditions for agents to be capable.
For individual developers and teams, it surfaces concrete, session-level feedback that can immediately improve how they work with agents—from how they write prompts to how they structure their repos.
Agent Experience is powered by the same lightweight daemon that drives AI Code Insights. For supported tools—currently Claude Code, GitHub Copilot, and Cursor—the daemon captures a per-session Agent Experience assessment at the end of each session, producing an overall score plus four component scores with qualitative commentary.
The new Agent Experience report surfaces this data at every level you need: an overall agent effectiveness score averaged across your entire organization, filterable by team, and drillable down to individual sessions where you can inspect the score, its components, and the agent’s own explanation of what it encountered. Over time, this data creates a longitudinal view of how your organization’s AI readiness is improving—or where it’s plateauing.
Agent Experience is generally available today as part of AI Code Insights. To learn more or get started, reach out to your account representative or request a demo.