An update on our commitment to data neutrality
Six months after DX’s acquisition announcement, here's what we’ve released as part of our commitment to data neutrality.

Ivan Diaz
Customer Engineering
When we announced DX’s acquisition by Atlassian in September, we published a post about our continued commitment to data neutrality—investing in third-party connectors and reporting parity across the tools engineering teams actually use. Atlassian has shared that same vision: DX should work for every engineering organization, regardless of their stack.
Six months later, here’s what we’ve shipped across planning, source control, AI coding tools, release systems, and infrastructure.
Reporting parity across planning tools
We said we were actively working on allocation, R&D capitalization, and sprint analytics for Linear and Azure DevOps. Those capabilities are now live and expanding.
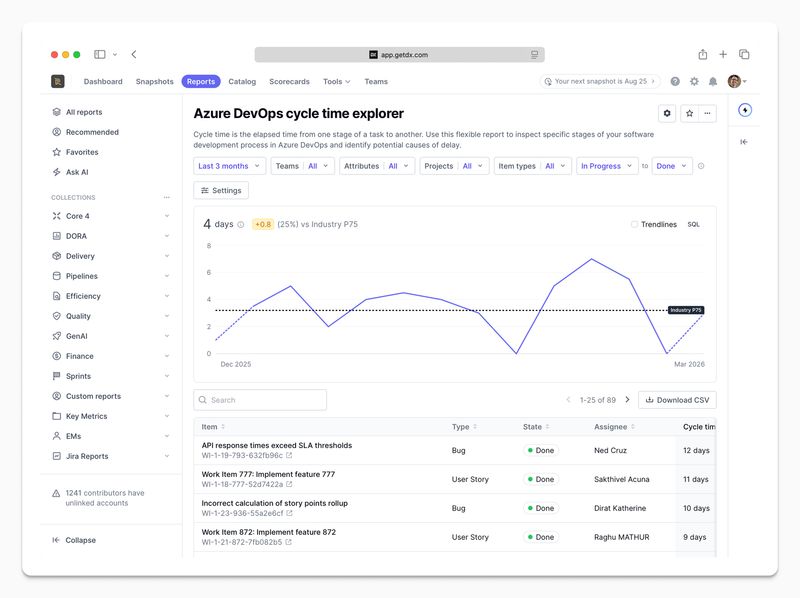
For customers using Azure DevOps, we have shipped:
- Time allocation reporting
- R&D capitalization (CapEx)
- Iteration (sprint) reporting
- Default-branch commit ingestion for teams practicing trunk based development
- Pull request commit-level analytics for more granular work logs and lead time metrics
- Initiative and deliverable tracking
For customers using Linear, we have shipped:
- Allocation reporting
- CapEx reporting
- Cycle (sprint) reporting
- Lifecycle metrics (completion, predictability, spillover, volatility)
- Hierarchical team support
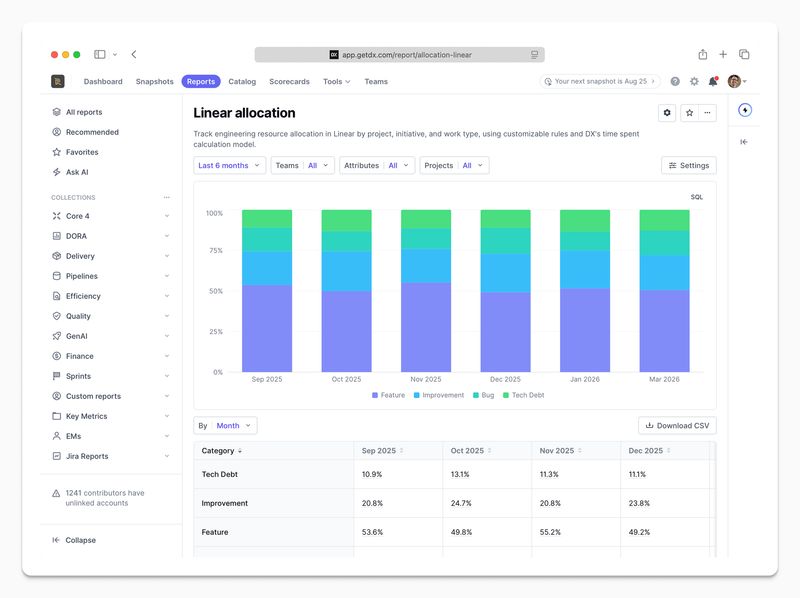
These updates move Linear and Azure DevOps closer to parity with our most mature ecosystems. They also continue to sit on top of the same unified schema, so leaders see a consistent view regardless of which tools teams use.
Deeper ingestion across source control
We also committed to stronger support for non‑Atlassian repositories and review flows. Since September, we have focused on both breadth and depth.
Updates:
- Released a production-ready Gerrit connector
- Expanded commit-level telemetry across GitHub, GitLab, Azure DevOps, and Bitbucket
- Added default-branch connectors to each of those for teams practicing trunk-based development teams
- Enhanced pull request analytics across platforms
These changes give teams more complete coverage of their development workflows and unlock more accurate metrics for lead time, review behavior, and delivery health.
Unified visibility into AI usage, spend, and impact
In our original post, we highlighted our work with leading AI coding vendors and our goal of maintaining parity across them. That work has continued and expanded.
Since September, we have:
- Launched the Claude Code connector
- Delivered Claude Code usage and spend analytics
- Integrated Amazon Q Developer activity tracking
- Expanded support across AI-powered review tools like CodeRabbit and Greptile
- Added a code metrics daemon
- Launched our AI Metrics API to support teams with proprietary, in-house coding assistants
- Enhanced GitHub Copilot user-level activity tracking to support business and enterprise licenses
- Developed reporting highlighting token spend
- Updated reporting to automatically attribute data from OOTB connectors and bespoke API tools
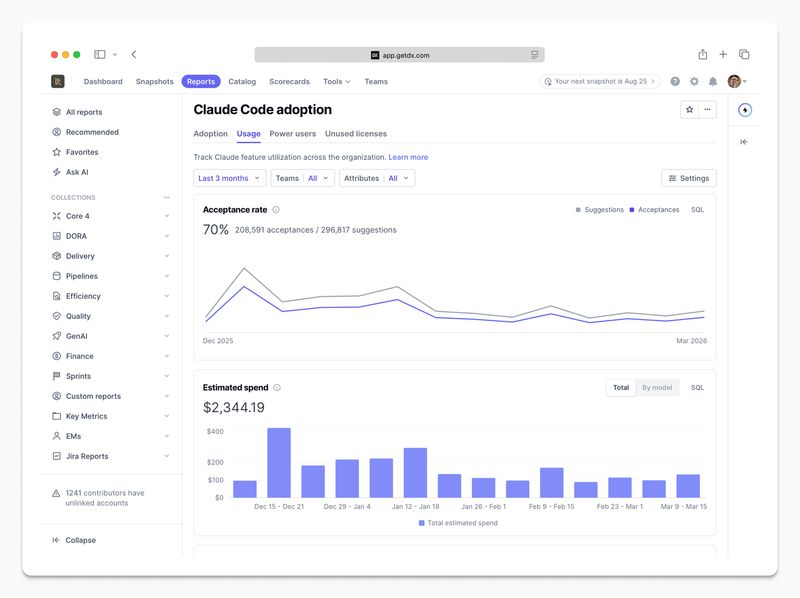
We’re focused on enabling leaders to compare ROI, token spend, and developer engagement in a consistent way, regardless of what AI coding or review tools they choose.
Beyond planning and code
Data neutrality does not stop at issue trackers and repositories. Modern engineering systems include feature flags, cloud infrastructure, and governance controls, and DX’s schema needs to cover those as well.
In the last six months we’ve:
- Expanded our LaunchDarkly integration to ingest feature flag lifecycle states and critical production environment markers. This strengthens governance and ties release behavior directly to engineering activity.
- Introduced an AWS connector to ingest infrastructure resources across EC2, RDS, Lambda, S3, EKS, and ElastiCache.
- Expanded governance and scorecard capabilities, including entity‑level trends and configurable IC metric anonymization.
Across planning, code, releases, and infrastructure, these integrations all plug into the same unified data model. That is what allows leaders to see a single, coherent picture of engineering, even when the underlying stack varies widely.
Data neutrality doesn’t stop at issue trackers and repositories. Modern engineering systems include feature flags, cloud infrastructure, and governance controls, and DX’s schema needs to cover those too.
Looking ahead
Modern engineering remains heterogeneous by design. Teams will continue to choose different planning systems, repositories, review tools, AI platforms, release systems, and infrastructure providers.
DX’s job is to make those choices work together—unifying how data is modeled, ingested, and reported so that when you open DX, you see a neutral, consistent view of your engineering organization.
That was our commitment in September. It remains our commitment today. We’ll keep broadening connector coverage and deepening reporting parity so customers can rely on DX as a data‑neutral foundation for modern engineering.